
健康診断表の「医師所見」を効率よくデータ化できないか?
概要
 |
健康診断表(以下、健診表)は活字で印字されていますが、医療機関により書式が異なるため、そのままOCR処理をしようとすると前処理が煩雑になります。
なるべく手をかけずに個人情報に配慮しつつ、「医師所見」のような1項目のデータ量が多い項目だけOCR処理をするための方法についてご説明いたします。 |
お客様より
 |
健診表は活字で印字されているが、医療機関により書式が異なるので入力作業によりデータ化を行っている。 |
 |
その中でも「医師所見」は検査項目に比べてデータ量が多く、作業の効率化の余地がある。 |
 |
帳票の種類が多く、検査名も医療機関により異なる表記があるので、すべてをOCR処理するのは難しいとは思うが、 作業を効率化するためになにか良い方法はないか? |
というご相談をいただきました。
当社でも様々なOCRエンジンを評価・検討させていただきましたが、
 |
①定型帳票の決まった項目 |
 |
②活字で印字されているもの |
を処理する場合、
 |
精度においては入力作業には及びませんが |
 |
処理の効率化の一助になるのではないか? |
と考えています。
以上の知見を踏まえ、
|
①活字で書かれている |
|
②医師所見のような1項目のデータ量が多い項目 |
に絞って、
 |
OCR処理を行い、 |
 |
データ入力作業と組み合わせ(ハイブリッド)て運用する |
ことで、
 |
効率化が図れるのではないか? |
と考えました。
この他配慮すべき点として、
①読み取らせる必要な項目を切り出し、OCRには定型帳票として処理させる
 |
OCRが苦手とする帳票解析を行わないようにする |
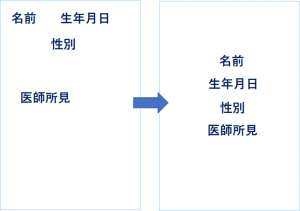 |
例えば、
名前 生年月日 性別 医師所見 をOCRで処理させる場合は、帳票の中からそれぞれの項目をあらかじめ切り出します。 |
②クラウドのOCRを利用することを想定し、秘匿化処理の実施
|
1枚の健診表から名前、生年月日、性別、医師所見のデータを切り出した場合、個人情報となります。 |
 |
個人情報のままクラウドOCRを利用すると個人情報の漏洩が懸念されます。 |
の対策を講じる必要があると考えました。
具体的には、
 |
①OCRで読み取りたい箇所を人間が指定し、必要な項目を切り出す |
 |
②①のデータを機械学習させ、同様の帳票が発生した場合は自動的に読み取り箇所を示唆(サジェスト)する |
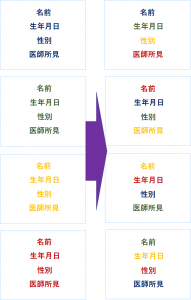 |
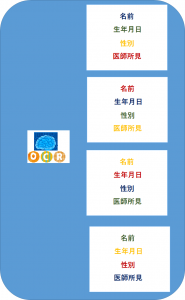
③①で切り出されたOCR対象の項目を当社独自の秘匿化技術「シャッフル」を用いて、秘匿化する。
例えば、 ・Bさんの生年月日 ・Cさんの性別 ・Dさんの医師所見 から切り出された項目を1枚の帳票にまとめ直しあげ |
 |
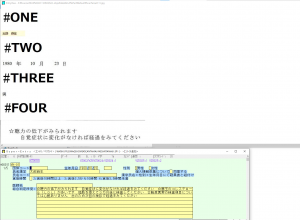
④③で作成された”架空”のOCR処理対象データをOCR処理させます。 |
 |
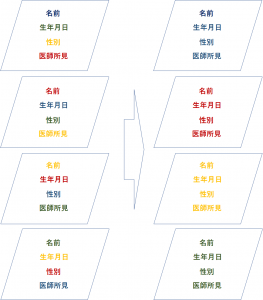
⑤④でOCR処理されたテキストデータを当社のデータエントリーシステム”Super-Entry”シリーズに取り込み、OCR処理で用いた画像と見比べて、テキストを修正します。 |
 |
⑥⑤で修正されたテキストデータをシャッフル処理前のテキストに”復元”します。 ・・・Aさんの名前、生年月日、性別、医師所見に戻す。 |
 |
⑦⑥で処理されたテキストと入力作業で得られたテキストデータを結合します。 |
こうすることでデータ入力作業の効率が向上するのではないかと考えています。
今回は健診表のデータを例にご説明しましたが、それ以外にも
 |
①帳票の種類が多く |
 |
②活字で書かれている |
の帳票に応用が可能です。
また、
 |
クラウドシステムを利用することで |
 |
テレワークにも柔軟に対応可能です。 |
新型コロナウィルス蔓延に伴う緊急事態宣言下、業務効率を見直される際には是非ご検討ください。
詳細については、こちら より お問い合わせください。
